Concepts et maquette du protocole MPLS
Nous verrons ici la présentation du protocole MPLS ainsi que la réalisation d'une maquette sur des équipements Cisco.

Nous verrons ici la présentation du protocole MPLS ainsi que la réalisation d'une maquette sur des équipements Cisco.
Définitions :
- MPLS is a packet-forwarding technology which uses labels in order to make data forwarding decisions. With MPLS, the Layer 3 header analysis is done just once (when the packet enters the MPLS domain). Label inspection drives subsequent packet forwarding. MPLS provides these beneficial application
- MPLS (Multiprotocol Label Switching) is used for forwarding packets over the backbone, and BGP (Border Gateway Protocol) is used for distributing routes over the backbone. The primary goal of this method is to support the outsourcing of IP backbone services for enterprise networks. It does so in a manner which is simple for the enterprise, while still scalable and flexible for the Service Provider, and while allowing the Service Provider to add value. These techniques can also be used to provide a VPN which itself provides IP service to customers.
https://tools.ietf.org/html/rfc2547
- Dans les réseaux IP traditionnels, le routage des paquets s'effectue en fonction de l'adresse de destination contenue dans l'entête de niveau 3. Chaque routeur, pour déterminer le prochain saut (next-hop), consulte sa table de routage et détermine l'interface de sortie vers laquelle envoyer le paquet. Le mécanisme de recherche dans la table de routage est consommateur de temps CPU, et avec la croissance de la taille des réseaux ces dernières années, les tables de routage des routeurs ont constamment augmenté. Il était donc nécessaire de trouver une méthode plus efficace pour le routage des paquets. Le but de MPLS était à l'origine de donner aux routeurs IP une plus grande puissance de commutation, en basant la décision de routage sur une information de label (ou tag) inséré entre le niveau 2 (Data-Link Layer) et le niveau 3 (Network Layer). La transmission des paquets était ainsi réalisée en
switchantles paquets en fonction du label, sans avoir à consulter l'entête de niveau 3 et la table de routage.
https://www.frameip.com/mpls-cisco/
Commandes
Cisco
show ip vrf show ip route vrf show ip bgp vpnv4 vrf VRF_NAME subnet/24
Exemple de configuration
Ajout d'une VRF sur un PE
ip vrf VRF.NAME description VRF.NAME rd XXXXX:YYYYY route-target export XXXXX:YYYYY route-target import XXXXX:YYYYY
On crée la loopback YYYYY
interface LoopbackYYYYY description loopback VRF_NAME ip vrf forwarding VRF.NAME ip address 10.255.52.0 255.255.255.255 end
On configure la partie BGP (MP-BGP) pour échanger les routes statiques et connectées :
address-family ipv4 vrf VRF.NAME redistribute connected redistribute static
On assume qu'une implémentation BGP est déà en place, ici on s'occupe seulement la communauté de la VRF.
Glossaire
route-reflectors : À l'intérieur d'un système autonome, les routes ne sont pas transitives, c'est-à-dire qu'une route reçue d'un voisin iBGP n'est pas transmise aux autres voisins iBGP. Pour que les routes soient connues par l'ensemble des routeurs de l'AS, ceux-ci établissent donc des connexions entre eux dans un maillage complet (full mesh, chaque routeur communique avec tous les autres), ce qui pose un problème d'échelle quand ces routeurs sont nombreux, le nombre de connexions augmentant comme le carré du nombre de routeurs. L'addition d'un nouveau routeur oblige à modifier la configuration de tous les routeurs BGP de l'AS.
Full-mesh/Partial-mesh : within a given VPN, we can allow every site to have a direct route to every other site ("full mesh"), or we can restrict certain pairs of sites from having direct routes to each other ("partial mesh").
Route Summarization : a group of subnets is rolled up into a summarized routing table entry.
Virtual Routing Forwarding (VRF) : is a technology that allows multiple instances of a routing table to co-exist within the same router at the same time. Because the routing instances are independent, the same or overlapping IP addresses can be used without conflicting with each other. Network functionality is improved because network paths can be segmented without requiring multiple routers.
Ressources
https://tools.ietf.org/html/rfc2547\
http://www.frameip.com/mpls-cisco/\
https://www.brimbelle.org/mattieu/projects/bgpmpls/pdf/VPN-BGP-MPLS_pres.pdf\
http://www.cisco.com/c/en/us/support/docs/multiprotocol-label-switching-mpls/mpls/13733-mpls-vpn-basic.html\
http://www.cisco.com/c/en/us/support/docs/multiprotocol-label-switching-mpls/mpls/4649-mpls-faq-4649.html#anc16
Maquette : Mise en place d'un réseau MPLS
Objectif : Mise en place d'un backbone MPLS
- Création des intercos du backbone
- Routage des loopbacks du backbone (OSPF)
- Activation du MPLS
- Création des VRFS
- Mise en place des sessions BGP du backbone
- Mise en place du routage CE <-> PE
Creation des interconnexions du backbone sur GNS3
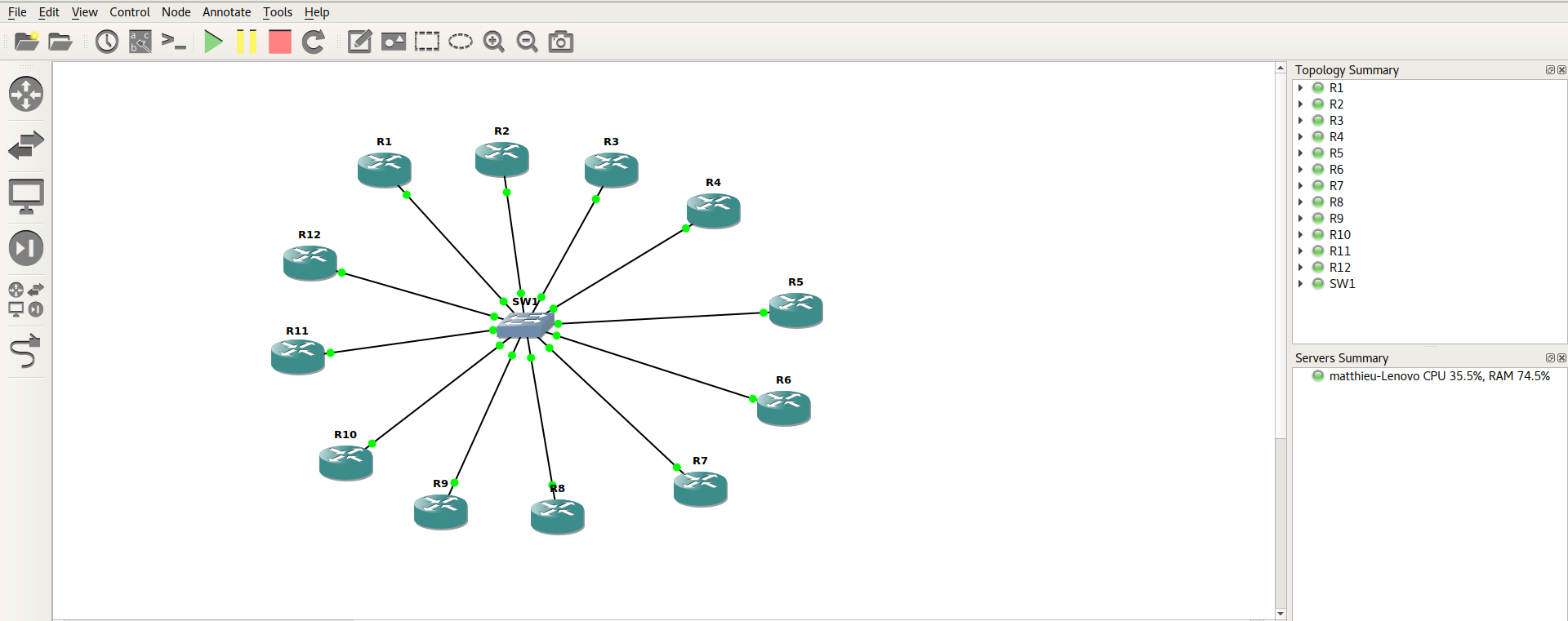
Interconnexions de niveau 3 :
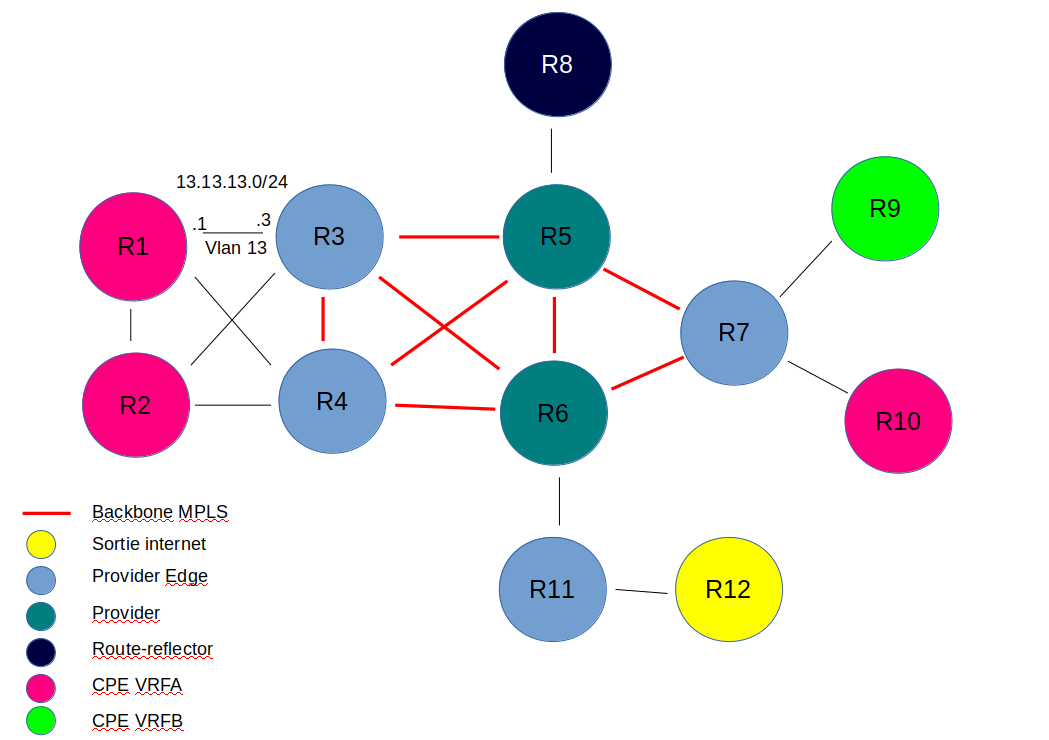
Routage des loopbacks du backbone
On active ospf sur les interfaces loopback et les interfaces physiques pour pouvoir joindre toutes les loopbacks du backbone
R3# interface Loopback0 ip address 3.3.3.3 255.255.255.255 ip ospf 1 area 0 ! interface FastEthernet0/0.34 encapsulation dot1Q 34 ip address 34.34.34.3 255.255.255.0 ip ospf 1 area 0 ! interface FastEthernet0/0.35 encapsulation dot1Q 35 ip address 35.35.35.3 255.255.255.0 ip ospf 1 area 0 ! interface FastEthernet0/0.36 encapsulation dot1Q 36 ip address 36.36.36.3 255.255.255.0 ip ospf 1 area 0
Les loopbacks sont maintenant toutes joignables.
Activation du MPLS
LDP est le protocole qui permet d'échanger les informations de label entre les routeurs du backbone. LDP est utilisé pour construire et maintenir la table LSP qui est utilisé pour le mpls.
Au lieu d'activer le protocole LDP sur chaque interface on va le synchroniser avec l'igp ospf ce qui aura pour effet d'activer le mpls sur les interfaces ospf.
router ospf 1 mpls ldp auto-config
On vérifie avec la bonne présence du protocol :
show mpls ldp neighbor show mpls interfaces
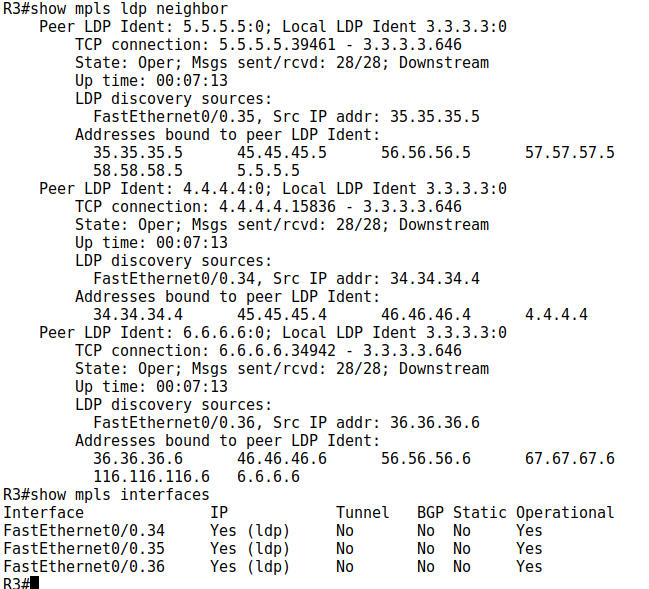
On force l'interface loopback0 a être le router-id des sessions LDP, sans ça, si l'on crée une interface loopback avec une adresse IP inférieure, celle-ci deviendra le router-id.
mpls ldp router-id loopback 0 force
Création des VRF
On crée les VRF clients :
ip vrf CUSTOMERA rd 1:1 route-target export 100:100 route-target import 100:100 ! ip vrf CUSTOMERB rd 2:2 route-target export 200:200 route-target import 200:200
On ajoute les interfaces clients dans les bonnes VRF
int fa0/0.13 ip vrf forwarding CUSTOMERA
Mise en place des sessions BGP du backbone
On monte les sessions entre les PE et R8 (Route reflector),
- Les neighbors BGP doivent être configurés globalement
- Les neighbors BGP doivent être activés pour VPNv4
Sur R8 (Route-reflector) :
router bgp 1 no synchronization bgp log-neighbor-changes neighbor PEER peer-group neighbor PEER remote-as 1 neighbor PEER update-source Loopback0 neighbor 3.3.3.3 peer-group PEER neighbor 4.4.4.4 peer-group PEER neighbor 7.7.7.7 peer-group PEER no auto-summary ! address-family vpnv4 neighbor PEER send-community extended neighbor PEER route-reflector-client neighbor 3.3.3.3 activate neighbor 4.4.4.4 activate neighbor 7.7.7.7 activate exit-address-family
On active les voisins dans l'adresse family vpnv4 et on envoi les community, c'est ainsi que les prefixes seront exportés et importés.
Sur les PE :
R7# router bgp 1 no bgp default ipv4-unicast bgp log-neighbor-changes neighbor 8.8.8.8 remote-as 1 neighbor 8.8.8.8 update-source Loopback0 ! address-family vpnv4 neighbor 8.8.8.8 activate neighbor 8.8.8.8 send-community extended exit-address-family
- send-community extend permet d'exporter les rt
- Les route target sont des community
- le route-target est indépendant du route distinguisher
Mise en place du routage CE - PE
Ensuite pour annoncer les réseaux clients des CE au PE on fait une session BGP
Attention sur le PE on monte la session sur l'adresse family ipv4 de la vrf du client
R1# router bgp 1 address-family ipv4 vrf CUSTOMERA neighbor 13.13.13.1 remote-as 500 neighbor 13.13.13.1 activate no synchronization exit-address-family
Sur le CE une session classique :
R1# router bgp 500 no synchronization bgp log-neighbor-changes network 10.10.10.10 mask 255.255.255.255 network 17.180.1.1 mask 255.255.255.255 neighbor 13.13.13.3 remote-as 1 no auto-summary
Même chose sur R10. A ce stade les routes sont maintenant échangées, sauf qu'il manque l'option allowas-in sur les CPE car par défaut ils refusent d'apprendre des prefixes des voisins eBGP dont l'as-path est leurs propre AS.
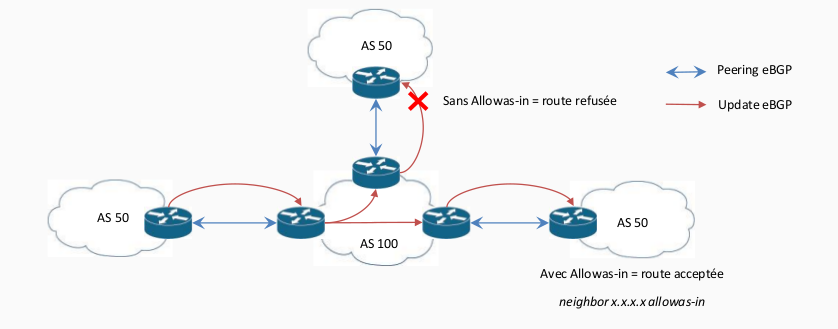
Sur les CPE :
R1# router bgp 500 neighbor 13.13.13.3 allowas-in
Depuis R1 on peut maintenant joindre R10.
Autre façon d'annoncer le réseau entre CE -> PE avec OSPF
Sur R7 et pour la vrf B :
- On crée un nouveau process ospf sur le PE R7 pour la vrf CUSTOMERB
- On crée le process ospf sur le CE client R9
- On peut voir la loopback de R9 depuis la vrf B sur R7
- On redistribue les prefix ospf dans bgp vpnv4
- On export/import les routes de la vrf B (si cela n'a pas été deja fait)
interface FastEthernet0/0.79 encapsulation dot1Q 79 ip vrf forwarding CUSTOMERB ip address 79.79.79.7 255.255.255.0 ip ospf 2 area 0 ! router ospf 2 vrf CUSTOMERB log-adjacency-changes address-family ipv4 vrf CUSTOMERB redistribute ospf 2 vrf CUSTOMERB no synchronization exit-address-family
Sur le CE R9 :
interface FastEthernet0/0.79 encapsulation dot1Q 79 ip address 79.79.79.9 255.255.255.0 ip ospf 1 area 0 ! router ospf 1 log-adjacency-changes network 9.9.9.0 0.0.0.255 area 0
Depuis R3 on retrouve maintenant dans la table de routage de la vrf B le réseau 9.9.9.9 et aussi le réseau d'interco 79.79.79.0/24
Si l'on souhaite ne pas renvoyer le réseau d'interco (car c'est inutile) on crée une route-map avec le prefix list de l'interco que l'on permit, puis on deny ce prefix-list sur la route-map puis on la match au redistribute ospf.
Sur R7 :
ip prefix-list INTER79 seq 5 permit 79.79.79.0/24 no cdp log mismatch duplex ! route-map FILTER deny 10 match ip address prefix-list INTER79 ! route-map FILTER permit 20 ! address-family ipv4 vrf CUSTOMERB redistribute ospf 2 vrf CUSTOMERB route-map FILTER no synchronization exit-address-family
Depuis R8 et les PE le réseau d'interco n'est plus annoncé.
On souhaite maintenant se connecter en ssh sur la loopback 11.11.11.11 (R1) depuis l'exterieur (R12)
on fait donc un nat sur l'interface de sortie (point internet) de R11 -> R12.
ip nat inside source static tcp 11.11.11.11 22 17.180.1.1 22 vrf A extendable
Même chose pour nater dans l'autre vrf sur R9 sur une autre
ip nat inside source static tcp 19.180.1.1 22 19.180.1.1 22 vrf B extendable
Plus il faut annoncer le reseau dans OSPF entre R7 -> R9
Route par défaut pour la vrf client
Nous souhaitons une route par défaut pour toute la VRF, pour cela depuis R11 (qui est un PE) nous créeons une route par défaut pour la vrf A et B.
ip route vrf CUSTOMERA 0.0.0.0 0.0.0.0 112.112.112.12 global
l'option global permet d'annoncer que le next hop se situe dans la table de routage global et non dans la VRF, cette option est donc obligatoire.
On redistribue les routes statiques et on autorise l'envoi de la route par défaut dans l'adresse family ipv4 de la vrf A.
Sur R11:
address-family ipv4 vrf CUSTOMERA redistribute static default-information originate no synchronization exit-address-family !
La route est maintenant échangée dans tout le backbone.
Petite subtilité pour la VRFB qui dispose d'une interco OSPF entre CE <-> PE, par défaut la route par défaut n'est pas échangée il faut l'activer sur la session OSPF :
Sur R7:
router ospf 2 vrf CUSTOMERB log-adjacency-changes redistribute bgp 1 subnets default-information originate !
Nat de sortie pour la vrf client
On souhaite nater toute la VRFA sur l'interface R11 <-> R12, pour cela on met en place un NAT classique et l'on spécifie la VRF
Sur R11:
interface FastEthernet0/0.112 encapsulation dot1Q 112 ip address 112.112.112.11 255.255.255.0 ip nat outside ip virtual-reassembly ! interface FastEthernet0/0.116 encapsulation dot1Q 116 ip address 116.116.116.11 255.255.255.0 ip nat inside ip virtual-reassembly ip ospf 1 area 0 ! ip nat inside source list 99 interface FastEthernet0/0.112 vrf CUSTOMERA overload ! access-list 98 permit any